
Am 18. und 19. November 2024 hatte ich die großartige Gelegenheit, den Marketing Analytics Summit in München zu besuchen. Er gilt als eine der führenden Konferenzen für Digital Analysts – und das nicht ohne Grund: Tiefgehende Einblicke in aktuelle Trends, Innovationen und bewährte Ansätze in den Bereichen Digital Analytics und Online-Marketing-Optimierung sind die großen Stärken des Summits.
Zu den zentralen Themen der diesjährigen Veranstaltung zählten KI im Marketing, Kundenanalysen und Personalisierung, Marketingeffektivität und -effizienz, Digital Analytics, Datenmanagement und Organisationsstruktur.
Imagination Engine: Generative AI as a Strategic Power Tool
Jim Sterne, Gründer des Marketing Analytics Summit
Die Konferenz wurde mit einer inspirierenden Session von Jim Sterne eröffnet, einem Pionier der Branche und Gründer des Marketing Analytics Summit. Für mich persönlich war es ein besonderer Moment. Meine Reise in die Welt der Web Analytics begann mit Jims Büchern, die mich Ende der 2000er Jahre bei meiner Masterarbeit inspirierten.

Jim Sterne, Gründer des Marketing Analytics Summit auf der Bühne
Generative KI: Mehr als ein Werkzeug
Dieses Jahr widmete Jim Sterne seinen Vortrag einem der aktuell heißesten Themen: Generative KI (GenAI). Unter dem Titel „Imagination Engine: Generative AI as a Strategic Power Tool“ beleuchtete er, wie diese Technologie unsere Beziehung zu Computern fundamental verändert.
GenAI ist nicht einfach eine Datenbank, Suchmaschine oder ein Rechner – und auch keine bloße Bibliothek. Ihre wahre Stärke liegt auch nicht darin, Texte oder Bilder zu erstellen, auch wenn das momentan im Trend liegt. Für ihn ist das vergleichbar mit der Nutzung eines 18-Tonners, um zum Supermarkt zu fahren: möglich, aber weit unter dem Potenzial.
Stattdessen kann Generative KI unsere Vorstellungskraft, Kreativität und analytisches Denken auf ein neues Niveau heben. Jim rief dazu auf, den Blick auf Computer neu zu definieren: Weg von reinen Berechnungs- und Abrufwerkzeugen, hin zu echten Partnern für Brainstorming, strategisches Denken und kritische Analyse.
Fazit: Die Macht der richtigen Fragen
Jim Sterne ermutigte die Zuhörerinnen und Zuhörer, die Möglichkeiten der Generativen KI voll auszuschöpfen, indem sie:
- unterschiedliche Arten von Fragen stellen,
- verschiedene Denkweisen ausprobieren,
- und die kreative Dimension der Technologie nutzen.
Für jene, die befürchten, durch KI ihren Job zu verlieren, hatte Jim eine beruhigende Antwort in der Fragerunde parat: „Ein Job ist ein Zusammenspiel vieler Aufgaben. KI kann Aufgaben übernehmen, aber keinen Job.“
Von der Tool-Evaluierung bis zum Business Impact: Die Digital Analytics Journey
Markus Frick, b.telligent
Markus Frick führte in seinem Vortrag die Teilnehmenden durch die zentralen Phasen der Digital Analytics Journey: von der Evaluierung und Auswahl eines geeigneten Digital-Analytics-Tools, über die Implementierung, das Enablement und das operative Doing bis hin zur Generierung von Business Value.
Bei der Auswahl eines Digital-Analytics-Tools, so Markus, sollten vier zentrale Aspekte berücksichtigt werden: Menschen, Prozesse, Technologie und Datenschutz.
Um die verschiedenen Tools in der Digital-Analytics-Landschaft besser einzuordnen, empfiehlt b.telligent, spezifische Fokus-Bereiche zu berücksichtigen. Diese umfassen:
- Produkt-Analytics
- Datenschutz
- Enterprise-Suiten
- E-Commerce/Online Shops
- 1st-Party-Tracking
- Warehouse-native Lösungen
Die Auswahl des passenden Tools sollte dabei stets an die individuellen Anforderungen und Besonderheiten des Unternehmens angepasst werden.
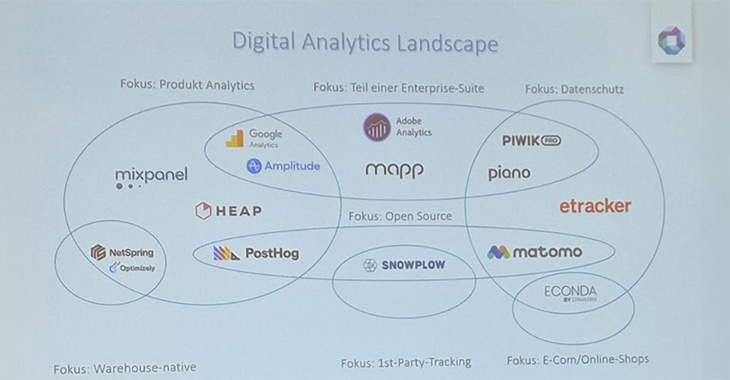
Die Digital Analytics Landscape
Tipps zur Implementierung und operativen Nutzung
- Datenschutz frühzeitig einbinden: Datenschutzaspekte sollten frühzeitig analysiert und die Datenschutzbeauftragten rechtzeitig involviert werden. So lassen sich spätere Anpassungen und Verzögerungen vermeiden.
- Dokumentation pflegen: Eine klare und aktuelle Dokumentation der Tracking-Implementierung ist essenziell. Dafür können Tools wie avo, trackingplan oder measurementplan hilfreich sein.
Ein holistischer Dashboard-Hub für Versicherungskonzerne: Datenaggregation und Visualisierung für bessere Managemententscheidungen
Patrik Götz (netzeffekt) & Dr. Reimer Stobbe (CommTech)
In ihrem Vortrag präsentierten Patrik Götz und Dr. Reimer Stobbe die Entwicklung eines umfassenden Dashboard-Systems für Munich Re, einen der weltweit führenden Rückversicherer mit rund 40.000 Mitarbeitenden. Ziel des Projekts war es, eine zentrale Plattform zu schaffen, die unternehmensweite Daten aus unterschiedlichsten Bereichen aggregiert und visualisiert.
Das entwickelte System vereint Informationen aus Bereichen wie:
- Brand-Reputation-Studien,
- HR-Daten,
- Social- und SEA-Kampagnen,
- Web-Analytics,
- SEO,
- Newsletter-Daten,
- Intranet
Die implementierte Lösung umfasste unter anderem die Datenpflege in MS Dynamics 365, die Zusammenführung und Konsolidierung der Daten aus unterschiedlichen Quellen in einer SQL-Datenbank sowie die Visualisierung in Power BI als zentrale „Single Source of Truth“. Eine der größten Herausforderungen dieses ambitionierten Projekts bestand in der Verknüpfung der Daten sowie der Definition von dafür geeigneten Dimensionen. Das Projekt basierte auf 5K der Datenvisualisierung.

Die 5 K der Datenvisualisierung
Der entwickelte Dashboard-Hub bietet unter anderem Executive Dashboard mit Top-Level-Daten, Campaign Dashboard für detaillierte Kampagnenanalysen und ein Reputation Management Cockpit zur Überwachung der Markenwahrnehmung.
Dadurch wird die Managementebene in die Lage versetzt, gezielt steuernd einzugreifen und eine effektive Kommunikation zu fördern. Zukünftige Schritte umfassen die Integration von künstlicher Intelligenz zur Erstellung von Prognosen, Empfehlungen und Warnsystemen sowie die Weiterentwicklung der Flexibilität des Dashboards, um neue Reporting-Bausteine und KPIs schnell und effizient integrieren zu können.
Product Thinking eats Use Cases for Breakfast – Was macht ein gutes Datenprodukt aus?
Dr. Ramona Greiner und Dr. Matthias Böck, FELD M
Einer der spannendsten und kreativsten Beiträge der Konferenz widmete sich der Frage “Was sind gute Datenprodukte?”. Dr. Ramona Greiner und Dr. Matthias Böck führten uns in die Welt der Datenprodukte ein und beleuchteten dabei nicht nur verschiedene Typen und Qualitätsmerkmale von Datenprodukten, sondern brachten auch überraschende Analogien ins Spiel. So wurde beispielsweise die Parallele zwischen einem idealen Datenprodukt und einem perfekt zusammengestellten Frühstücksmüsli gezogen. Auch ein kritischer Blick auf die moderne Datenkultur aus der Perspektive von Karl Marx sorgte für Denkanstöße.

Dr. Ramona Greiner und Dr. Matthias Böck auf der Bühne für ihren Vortrag
Laut Ramona und Matthias zeichnen sich die Zutaten für gute Datenprodukte durch folgende Merkmale aus:
- Saubere Daten: Ohne Datenqualität kein Erfolg
- Die richtigen KPIs: Metriken, die wirklich aussagekräftig sind
- Sinnvolle und leicht verständliche Visualisierungen: Daten müssen effektiv kommuniziert werden
- Enablement: Die User müssen befähigt werden, das Produkt optimal zu verwenden
- UX, Naming Convention, Zugänglichkeit und Performance: Ein durchdachtes Gesamtpaket für eine reibungslose Nutzererfahrung
Vom Use Case zu Product Thinking
Doch wie erreicht man all das? Ramona und Matthias schlagen vor, sich von der traditionellen Use-Case-zentrierten Denke zu lösen und stattdessen auf Product Thinking zu setzen – eine Herangehensweise, die Design Thinking und agile Methoden kombiniert.
Ein konkretes Beispiel dafür wurde anhand eines Design-Studio-Workshops vorgestellt, einer praktischen Methode aus dem Product Thinking. Dabei entsteht ein Datenprodukt iterativ in mehreren Schritten:
- Teilnehmerinnen und Teilnehmer identifizieren: Wer wird das Produkt nutzen?
- Ziele und User Stories sammeln und priorisieren: Was soll das Produkt leisten?
- Iterative Entwicklung: Ideen für Dashboards skizzieren, Feedback einholen und anpassen.
- Prototypen bauen: Erste konkrete Umsetzungen testen und weiterentwickeln.
So führt ein agiler Prozess zu einem praxisnahen, nutzerorientierten Datenprodukt.
Fazit: Entfacht den Appetit auf Daten! Mit den richtigen Zutaten und Methoden lässt sich aus Datenprodukten ein echter Mehrwert schaffen – ganz nach dem Motto: Product Thinking eats Use Cases for breakfast!

Entzündet den Datenappetit!
Die 5 größten Mythen über CDPs
Laurentius Malter, b.telligent
In seinem Vortrag nahm Laurentius Malter die Zuhörerinnen und Zuhörer mit auf eine spannende Reise durch die häufigsten Missverständnisse rund um Customer Data Platforms (CDPs). Dabei deckte er nicht nur auf, was eine CDP leisten kann, sondern auch, wo ihre Grenzen liegen und wie sie in moderne MarTech-Stacks integriert werden kann.
Mythos 1: Eine CDP löst alle Cookie-Probleme
CDPs sind stark in der Verarbeitung von 1st-Party-Daten, aber keine Allheilmittel für Cookie- oder Tracking-Herausforderungen. Entscheidend ist, die Erhebung und Nutzung von 1st-Party-Daten strategisch zu verbessern.
Mythos 2: Eine CDP ist die All-in-One-Lösung
CDP ist kein Ersatz für CRM-Systeme (CDP ist nicht das kundenführende System), Data Warehouses (CDP kann sie ergänzen, aber nicht ersetzen) und Customer Analytics. Diese Funktionen bleiben spezialisierten Tools vorbehalten.
Mythos 3: Eine CDP ist die Single Source of Truth
Während eine CDP Kundendaten und Ereignisdaten zentralisiert, wird sie nie alle Datenquellen ersetzen können, die für umfassendes Reporting und Data Science benötigt werden.
Mythos 4: Eine CDP sollte von jedem genutzt werden
Der Einsatz einer CDP bringt Nutzen für viele Abteilungen, wie Marketing oder Analytics, doch die Implementierung und der Betrieb erfordern spezifische Ressourcen aus IT, Datenschutz und Produktmanagement.
Mythos 5: Mit einer CDP kann ich alle Use Cases umsetzen
CDPs sind hervorragend für eventbasierte Use Cases wie Echtzeit-Personalisierung geeignet, während andere Szenarien weiterhin spezialisierte Systeme erfordern.
Laurentius betonte, dass erfolgreiche CDP-Implementierungen durch klare Zieldefinitionen und eine durchdachte Strategie geprägt sind.
Key Takeaways
- Strategie für 1st-Party-Daten und Zustimmungen entwickeln.
- Den eigenen MarTech-Stack genau kennen.
- CDPs und Data Warehouses als Ergänzungen verstehen, nicht als Gegensätze.
- Stakeholder frühzeitig einbinden.
- Use Cases detailliert und früh definieren.
Full Data Ownership im digitalen Marketing – Nur ein schöner Traum?
Christian Ebernickel beleuchtete die Herausforderungen rund um die Kontrolle über Daten im digitalen Marketing.
Was ist Data Ownership?
Data Ownership bedeutet die Kontrolle über und Verantwortung für Daten. Laut GDPR werden dabei folgende „Spieler“ unterschieden: Data Subjects (betroffene Personen), Data Controllers (Personen/Unternehmen/Institutionen, die den Zweck und die Mittel der Verarbeitung personenbezogener Daten bestimmen) und Data Processors (Auftragsverarbeiter, die auf Anweisung des Data Controllers handeln und personenbezogene Daten verarbeiten).
Herausforderungen in Tracking-Setups
Ein Hauptproblem liegt in der Abhängigkeit von Drittanbieter-Tags wie Google Analytics oder TikTok. Diese erfassen Daten oft ohne volle Kontrolle durch die Unternehmen und speichern sie auf fremden Servern. Meist bekommt man keine Information bei Änderungen am Code oder gesetzten Cookies.
Als Beispiel: Google Enhanced Conversions überträgt gehashte Nutzerdaten an Google. Obwohl als „privacy-safe“ vermarktet, gelten diese Daten laut GDPR weiterhin als personenbezogen und erfordern eine explizite Zustimmung. Ein weiteres Risiko besteht darin, dass das Verhalten der Tags direkt über die Benutzeroberflächen der Werbenetzwerke beeinflusst werden kann. So können beispielsweise Funktionen wie Enhanced Conversions ohne Administratorrechte mit nur wenigen Klicks aktiviert werden.
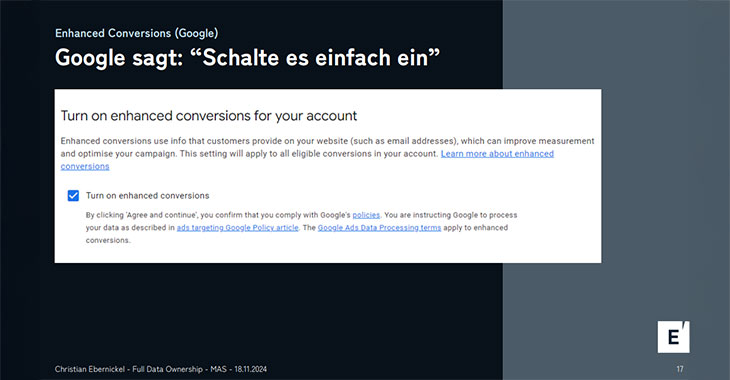
Enhanced Conversions und was man tun soll
Risiken
Die Nutzung solcher Technologien birgt erhebliche rechtliche und technische Risiken:
- Datenschutzprobleme: Übertragene Daten können ohne ausreichende Zustimmung verarbeitet werden, was Strafen nach sich ziehen kann.
- Verlust der Datenhoheit: Eine rechtlich konforme Aufklärung der User über die Übertragung von Daten an Dritte kann zu einer geringeren Consent Rate für das gesamte Tracking führen.
Fazit: Maßnahmen zur Risikominderung
- Server-side Tagging: Verlagerung der Datenverarbeitung auf eigene Server.
- Nutzung neutraler Tags (z. B. Snowplow) anstelle von Drittanbieter-Tags,
- sorgfältige, rechtliche Risiko-Bewertung und Anpassung der Prozesse.
- Klare Consent-Prozesse: User detailliert über die Datenverarbeitung informieren.
Fazit zum Summit
Der Marketing Analytics Summit in München war eine tolle Gelegenheit, spannende Einblicke in die neuesten Themen, Herausforderungen und Lösungen rund um Datenanalyse und Marketing-Technologien zu bekommen. Inspirierende Vorträge, praxisnahe Beispiele und der Austausch mit anderen Expertinnen und Experten haben gezeigt, wie datengetriebene Strategien erfolgreich umgesetzt werden können. Mit vielen neuen Ideen und Denkanstößen blicke ich gespannt darauf, die Möglichkeiten moderner Analytics-Lösungen besser zu verstehen und weiterzuentwickeln.
Jetzt Unterstützung in Online-Marketing erhalten
